Documentació del projecte XatBot
1 – Còpia de contingut de la web (BeautifulSoup)
S’ha creat un programa amb BeautifulSoup que visita les pàgines d’un web i guarda només el text important, com els títols (h1, h2, h3) i els paràgrafs (p), sense menús ni capçaleres.
import requests
from bs4 import BeautifulSoup
from collections import deque
import time
import json
def extreure_contingut(url):
try:
headers = {"User-Agent": "Mozilla/5.0 (compatible; XatBot/1.0)"}
resposta = requests.get(url, headers=headers, timeout=10)
if resposta.status_code != 200:
return None
soup = BeautifulSoup(resposta.text, "html.parser")
# Títol principal
h1 = soup.find("h1")
titol = h1.get_text().strip() if h1 else "Sense títol"
# Text dels paràgrafs
paragraphs = soup.find_all("p")
contingut = " ".join(
p.get_text().strip() for p in paragraphs
if p.get_text().strip()
)
return {
"url": url,
"titol": titol,
"contingut": contingut,
"data_scraped": time.strftime("%Y-%m-%d")
}
except Exception as e:
print(f"⚠️ Error a {url}: {e}")
return None
Pas 1 – Configuració dels primers passos del scraper
Pas 2 – Capturar títols i paràgrafs

2 – Automatitzar la còpia i guardar a un fitxer
El programa recorre moltes pàgines, evita repetir‑les i guarda tot el text en un fitxer en format JSON.
def scraper_recursiu(domain, start_url):
urls_visitades = set()
pendents = deque([start_url])
dades = []
while pendents:
url_actual = pendents.popleft()
if url_actual in urls_visitades:
continue
urls_visitades.add(url_actual)
resultat = extreure_contingut(url_actual)
if resultat:
dades.append(resultat)
# Pausa entre peticions
time.sleep(0.3)
# Guardar dades a JSON
with open("dades_total.json", "w", encoding="utf-8") as f:
json.dump(dades, f, ensure_ascii=False, indent=2)
Pas 3 – Afegir la llista de pàgines a visitar

Pas 4 – Guardar el resultat en un fitxer JSON
Pas 5 – Executar el programa de copia
3 – Controlar el programa: retard, errors i temps màxim
3.1 – Retard entre peticions
Per no sobrecarregar el servidor, s’espera 0,3 segons entre cada pàgina.
time.sleep(0.3)
resposta = requests.get(url_actual, headers=headers, timeout=10)
3.2 – Gestió d’errors
Si hi ha problemes amb una pàgina, el programa mostra un missatge i continua amb la següent.
except Exception as e:
print(f"⚠️ Error a {url_actual}: {e}")
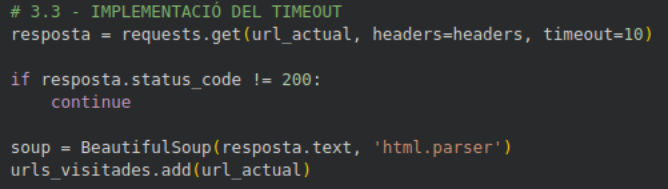
3.3 – Temps màxim d’espera
Si una pàgina no respon en 10 segons, el programa deixa d’esperar i passa a la següent.
resposta = requests.get(url_actual, headers=headers, timeout=10)
if resposta.status_code != 200:
continue
Pas 6 – Afegir el retard i el temps màxim
Pas 7 – Missatges quan hi ha errors
4 – Treball amb IA per corregir i millorar el codi
L’assistent d’IA ha ajudat a escriure el codi inicial i a corregir el que anava malament, especialment per connectar el programa amb el xatbot i arreglar errors de connexió.
- Permetre peticions del navegador: s’ha afegit
CORSperquè el web i el servidor puguin parlar bé. - Port ocupat: s’acaben connexions antigues abans d’obrir‑n’hi una de nova.
from flask import Flask
from flask_cors import CORS
import os
import time
app = Flask(__name__)
CORS(app)
# Tancar connexions antigues de ngrok
os.system("pkill -f ngrok")
time.sleep(1)
5 – Documentació del projecte a GitHub
El codi es guarda a GitHub, amb dos fitxers principals que expliquen com funciona el projecte.
5.1 – Fitxer README
Conté una explicació breu de com funciona el projecte, quines funcions té i com configurar‑lo.
# 🤖 Xatbot TalentFP 2026
Projecte d'assistent virtual amb IA per a un web educatiu.
# Funcions principals
- Copiar el contingut del web automàticament.
- Guardar el text en un fitxer JSON.
- Responer a preguntes basades en el text.
- Integrar el xatbot a una pàgina web.
# Eines
- Python 3.x
- BeautifulSoup4, Requests
- Google Gemini Pro
- Google Colab
- GitHub
5.2 – Fitxer CHANGELOG
Explica els canvis que s’han fet en el projecte amb el temps.
## [1.1.0]
### Afegit
- Programa de còpia de totes les pàgines.
- Retard de 0.3s i control d'errors de la web.
- Fitxer JSON amb totes les dades.
- Connexió amb GitHub des de Colab.
- Sistema de claus d'API segures.
### Canviat
- Canvi de noms de fitxers i organització de la carpeta.